

【導讀】隨著深度學習技術的快速發(fā)展,安靜環(huán)境下的語音識別已基本達到實用的要求;但是面對真實環(huán)境下噪聲、混響、回聲的干擾,面對著更自然隨意的口語表達,語音識別的性能明顯下降;尤其是遠講環(huán)境下的語音識別,還難以達到實用的要求。
語音前端處理技術對于提高語音識別的魯棒性起到了非常重要的作用;通過前端處理模塊抑制各種干擾,使待識別的語音更干凈;尤其是面向智能家居和智能車載中的語音識別系統(tǒng),語音前端處理模塊扮演著重要角色。除了語音識別,語音前端處理算法在語音通信和語音修復中也有著廣泛的應用。
在面向語音識別的語音前端處理算法,通過回聲消除、噪聲抑制、去混響提高語音識別的魯棒性;真實環(huán)境中包含著背景噪聲、人聲、混響、回聲等多種干擾源,上述因素組合到一起,使得這一問題更具挑戰(zhàn)性。
遠場語音識別的幾個典型的應用場景,包括:智能機器人、智能家居等,此外智能車載也有著非常廣泛的應用。為了使得這幾個典型應用場景的技術真正落地,需要解決一系列技術痛點,語音前端處理的一個最為重要的目標是實現釋放雙手的語音交互,使得人機之間更自然的交互。
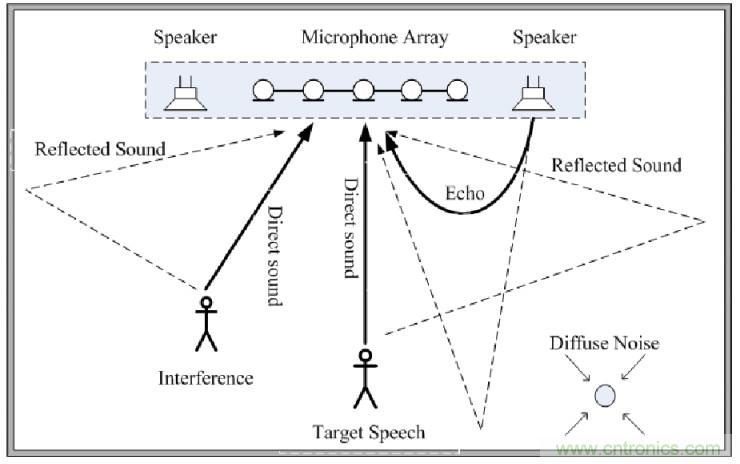
此圖形象的描述的語音前端處理模塊的幾個關鍵問題:Echo:遠端揚聲器播放的聲音回傳給麥克;Diffuse Noise:無向噪聲的干擾;Reflected Sound:聲音通過墻壁反射,造成混響干擾;Interference:其他方向的干擾源; Target Speech:目標方向聲音。Microphone Array:利用麥克風陣列拾音。
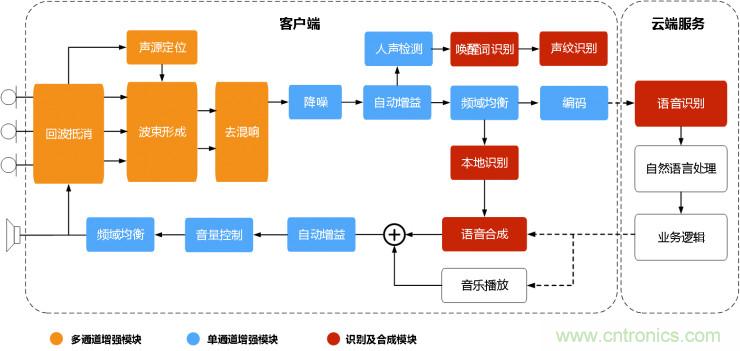
語音前端處理模塊跟語音交互系統(tǒng)的關系:橙色部分表示多通道處理模塊,藍色部分表示單通道處理模塊,紅色部分表示后端識別合成等模塊。麥克風陣列采集的語音首先利用參考源對各通道的信號進行回波消除,然后確定聲源的方向信息,進而通過波束形成算法來增強目標方向的聲音,再通過混響消除方法抑制混響;需要強調的是可以先進行多通道混響消除再進行波束形成,也可以先進行波束形成再進行單通道混響消除。經過上述處理后的單路語音進行后置濾波消除殘留的音樂噪聲,然后通過自動增益算法調節(jié)各個頻帶的能量后最為前端處理的輸出,將輸出的音頻傳遞給后端進行識別和理解。
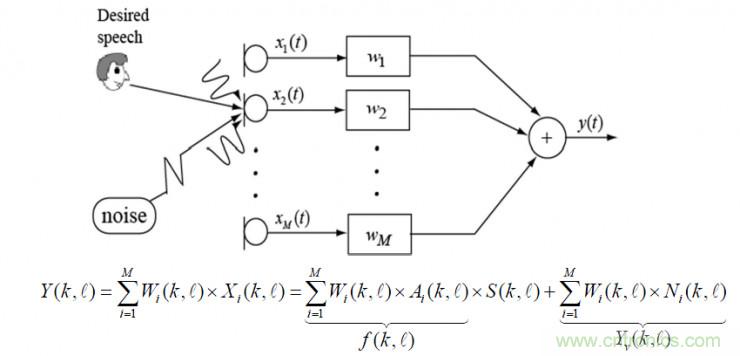
對于遠場語音識別,更多的是采用雙麥克,甚至是多麥克進行聲音采集,這是由于單麥克遠距離拾音能力有限,而麥克風陣列可以有效的增強目標方向聲音。上圖為麥克風陣列采集語音的示意圖,各個通道的信號通過濾波器加權融合,Y為多通道融合增強后的語音,可以將其分解為兩部分:目標語音成分和殘留噪聲成分;殘留噪聲成分可以通過后置濾波算法進一步處理,也可以通過改進麥克風陣列波束形成算法使這一成分得到有效抑制。
一、回聲消除的方法:
在遠場語音識別系統(tǒng)中,回聲消除最典型的應用是智能終端播放音樂,遠端揚聲器播放的音樂會回傳給近端麥克風,此時需要有效的回聲消除算法來抑制遠端信號的干擾?;芈曄膬蓚€難點是雙講檢測和延時估計,對于智能終端的回聲消除模塊,解決雙講條件下對遠端干擾源的抑制是最為關鍵的問題。
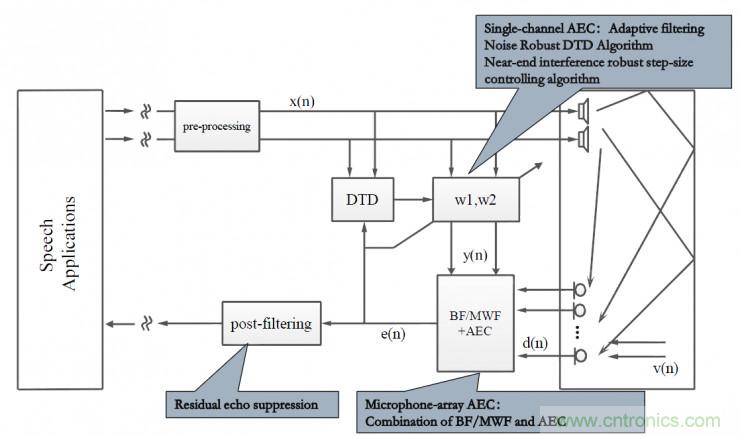
這是一個更為復雜的回聲消除系統(tǒng),近端通過麥克風陣列采集信號,遠端是雙聲道揚聲器輸出;因此近端需要考慮如何將波束形成算法跟回聲消除算法對接,遠端需要考慮如何對立體聲信號去相關。如圖所示DTD部分結合遠端信號和近端信號進行雙講檢測,通過判斷當前的模式(近講模式、遠講模式、雙講模式)采用不同的策略對濾波器w1和w2進行更新,進而濾除遠端干擾,在此基礎上通過后置濾波算法消除殘留噪聲的干擾。
二、混響消除方法:
聲音在房間傳輸過程中,會經過墻壁或其它障礙物的反射后到達麥克風,從而生成混響語音;房間大小、聲源和麥克風的位置、室內障礙物、混響時間等因素均影響著混響語音的生成;可以通過T60描述混響時間,它的定義為聲源停止發(fā)聲后,聲壓級減少60dB所需要時間即為混響時間?;祉憰r間過短,聲音發(fā)干,枯燥無味不親切自然,混響時間過長,會使聲音含混不清:合適時聲音圓潤動聽。大多數房間的混響時間在200-1000ms范圍內。
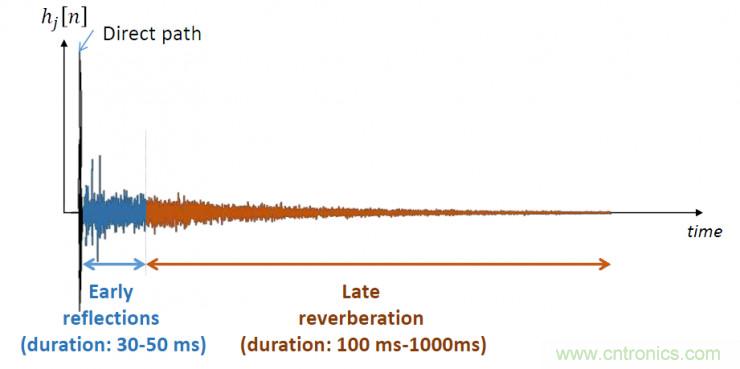
上圖為一個典型的房間脈沖響應,藍色部分為早期混響,橙色部分為晚期混響;在語音去混響任務中,更多的關注于對晚期混響的抑制。
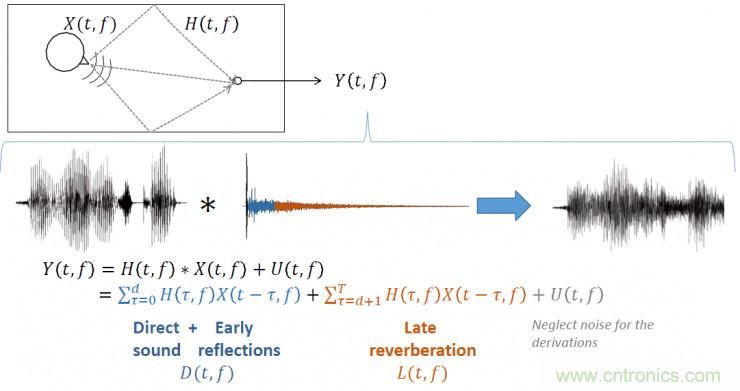
此圖相對直觀的描述了混響語音的生成過程,安靜語音在時域上卷積房間脈沖響應濾波器后生成混響語音;通常語音在傳輸過程中會伴隨噪聲的干擾;因此麥克風接收到的語音Y包含三個部分:藍色部分包括了從聲源直接到達麥克風的語音以及早期混響成分、橙色部分是晚期混響成分、灰色部分是房間中各種噪聲源的干擾。
當前主流的混響消除方法主要包括以下四類:基于波束形成方法、基于逆濾波方法、基于語音增強方法、基于深度學習方法?;诓ㄊ纬傻幕祉懴椒僭O干擾信號與直達信號之間是獨立的,它對于抑制加性噪聲非常有效,它并不適用于混響環(huán)境;理論上,逆濾波算法可以獲得較好的混響消除性能,但是缺少能夠在實際環(huán)境中對混響等效濾波器進行盲估計的有效算法,因此很難實際應用;譜增強算法根據預先定義好的語音信號的波形或頻譜模型,對混響信號進行處理,但是該方法難以提取出純凈語音,從而難以有效實現混響消除。針對上述問題,一些學者開始嘗試基于深度學習的語音混響消除方法,這種方法的劣勢是當訓練集和測試集不匹配時,算法性能會下降。這次報告重點介紹一種使用比較廣的基于加權預測誤差的混響消除方法。這種方法是由日本的NTTData公司提出并進一步改進的,能夠適用于單通道和多通道的混響消除。
這種方法的思想和語音編碼中的線性預測系數有些相似,如下圖所示,混響語音信號Y可以分解為安靜語音成分D混響成分L,L可以通過先前若干點的Y加權確定,G表示權重系數;WPE算法的核心問題是確定G,然后估計出混響消除后的語音。

該算法通過如下目標函數估計濾波器系數,具體推倒過程如下所示,更為詳細的算法流程可以參考一下網址(kecl.ntt)推薦的論文。
由于早期混響成分有助于提高語音的可懂度,因此可以對上述的方法進行改進,只抑制晚期混響成分。如下圖所示D同時包括安靜語音成分和早期混響成分,通過先前若干點的Y確定L時沒有考慮早期混響成分。
在此基礎上將WPE方法擴展到多通道混響消除模式,此時某一通道的晚期混響成分L可以通過各個通道先前若干點的Y加權確定,通過估計最優(yōu)的權重系數G,消除晚期混響成分的干擾。

基于WPE的多通道混響消除的流程,如果所示需要經過多次迭代確定出濾波器系數g,生成出混響消除后的語音。輸出的去混響后的各通道語音可以作為波束形成算法的輸入。
三、語音降噪方法:
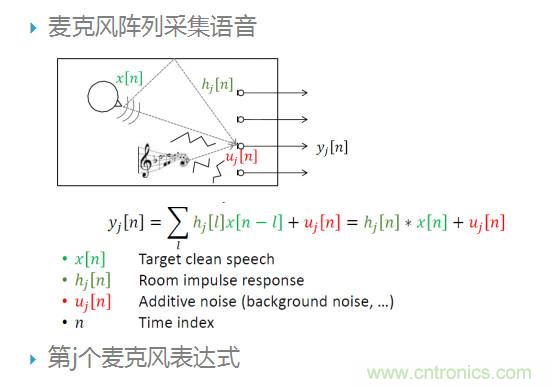
這個公式表示第j個麥克風接收到語音信號時域上的數學表達式,x表示安靜語音,h表示房間響應函數,u表示其它噪聲干擾。接下來介紹的算法將更多的側重于對噪聲源u的抑制。

此公式表示第j個麥克風接收到語音信號頻域上的數學表達式,X表示安靜語音,H表示房間響應函數,U表示其它噪聲干擾。接下來介紹的算法將更多的側重于對噪聲源U的抑制。
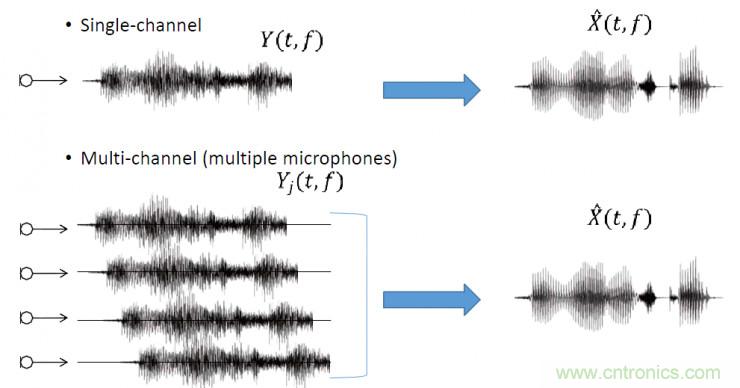
波束形成算法的目的:融合多個通道的信息抑制非目標方向的干擾源,增強目標方向的聲音。從圖中我們可以看到,各個麥克風接收到的語音信號存在延時,這種時延信息能夠反映出聲源的方向;直覺上分析,通過對齊各個通道的信號,能夠增強目標語音信號,同時由于相位差異可以抵消掉部分干擾成分。
波束形成算法需要解決的核心問題是估計空間濾波器W,它的輸入是麥克風陣列采集的多通道語音信號,它的輸出是增強后的單路語音信號。對空間濾波器進一步細分,可以分為時不變線性濾波、時變線性濾波以及非線性變換模型。最簡單的延時求和法屬于時不變線性濾波,廣義旁瓣濾波法屬于時變線性濾波,基于深層神經網絡的波束形成屬于非線性變換模型。

通過波束方向圖可以更直觀的理解波束形成的原理,上圖是一個麥克風陣列算法在f頻帶上所對應的波束方向圖,不同頻帶對應不同的波束方向圖;波束方向圖同時還依賴于麥克風陣列的硬件拓撲,例如線型陣只能實現180度定向,因此它的波束方向圖是對稱的。在設計波束形成算法時,需要盡可能使得主瓣帶寬盡可能窄,同時能夠有效的抑制旁瓣增益。在麥克風陣列選型上,麥克風之間的距離越大,則陣列的定向拾音能力越強,但是不能無限加大麥克風之間的距離,需要遵循空間采樣定理。聲學信號中的波束形成方法與雷達信號處理中的波束形成方法有很多相似之處,但兩者處理的頻帶和帶寬有差異。

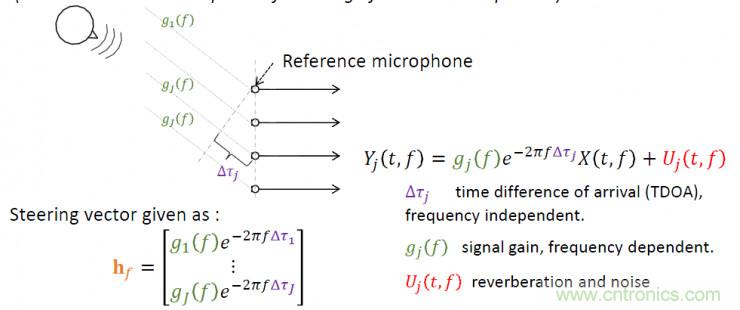
麥克風陣列算法的數學表達式解析,式中Y表示各個麥克風接收到的信號,綠色部分表示聲源信號,橙色部分表示聲源信號傳輸到麥克風的變換,紅色部分表示各種噪聲源的干擾。因此波束形成算法需要在已知Y的條件下,盡可能準確的估計h和u;即估計導向矢量和噪聲模型。
導向矢量是麥克風陣列算法中最為重要的參數,能夠反映聲源傳輸的方向性信息,用于描述從聲源到麥克風傳輸過程中延時、衰減等特性;下圖為自由場條件下的平面波模型,自由場假設忽略了混響干擾,遠距離拾音可以近似為平面波模型;數學表達式中紫色部分表示聲源到達各個麥克風的時間差,綠色部分表示聲源向麥克風傳輸過程中的衰減,導向矢量主要跟這兩個因素有關;在一些算法中會忽略能量衰減因素的影響。對導向矢量進一步處理也可以對聲源方位信息進行估計。
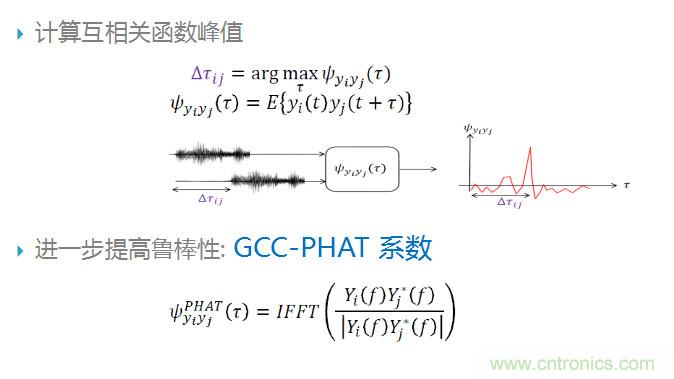
通過廣義互相關函數可以確定各個麥克風之間的相對延時,如下圖所示,尋找廣義互相關函數中的峰值點,通過峰值點的位置計算出相對延時。為了進一步提高TDOA估計的魯棒性,可以采用GCC-PHAT方法,這種方法在已有方法基礎上引入了能量歸一化機制。
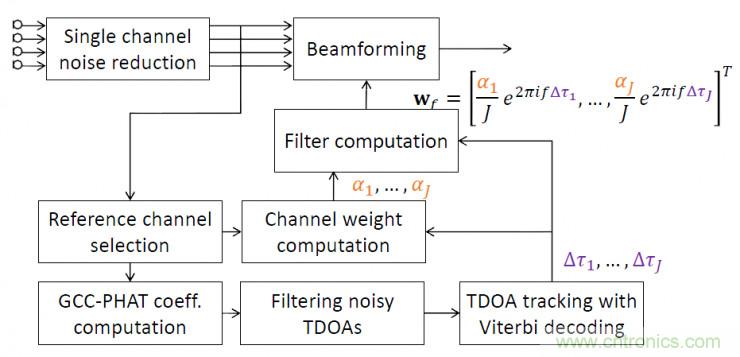
下圖為一種改進的基于加權延時求和的波束形成方法,針對TDOA模塊,利用維特比算法確定各個通道的最優(yōu)相對延時,根據實際環(huán)境對各個通道的權重進行控制;算法細節(jié)可以參考BeamformIt工具包,這種算法作為CHIME評測比賽中的基線方法。
基于延時求和的方法計算復雜度低,但是它在真實環(huán)境下的魯棒性差,接下來介紹一種應用更為廣泛的方法:基于最小方差失真響應波束形成。如下圖中的數學表達式所示,y表示多通道語音,w表示空間濾波器,x表示增強后的單通道語音,這種波束形成算法的假設是期望方向上的語音無失真,也就是wh這項為1;同時保證對噪聲的響應最小,也就是最小化wu這項。在這兩個約束條件下估計最優(yōu)的空間濾波器w。

經過一系列的變換和推倒,我們能夠確定空間濾波器w與噪聲協方差矩陣和導向矢量的關系。為了計算噪聲協方差矩陣,需要估計出各個通道中信號在各個頻帶上噪聲成分的互相關系數,因此對噪聲成分的有效估計將直接影響到波束形成算法的性能。對于導向矢量,可以通過估計聲源到達各個麥克風的相對延時來確定。
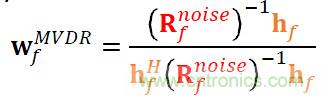
為了有效的估計噪聲協方差矩陣,需要對各個通道信號的各幀的各個頻帶的屏蔽值進行估計,可以采用二值型屏蔽或浮點型屏蔽;通過這一屏蔽值可以判斷各個頻帶是否是噪聲主導以及噪聲所占的比重;在確定了屏蔽值,可以進一步計算出噪聲協方差矩陣和語音協方差矩陣;對于導向矢量,不僅可能通過到達各個麥克風的相對延時來確定,還可以通過語音協方差矩陣變換得到,導向矢量可以近似的表示為語音協方差矩陣最大特征值所對應的特征向量。
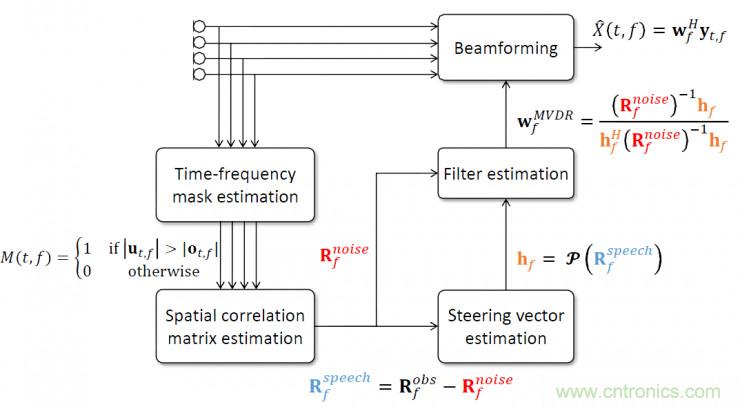
重點介紹基于最小方差失真響應波束形成的流程,對各個通道語音首先進行屏蔽值估計,然后計算噪聲協方差矩陣和語音協方差矩陣,進一步確定導向矢量,通過導向矢量和噪聲協方差矩陣估計空間濾波器,生成波束形成后的單通道語音。
除了基于延時求和的波束形成和基于最小方差失真響應的波束形成,以下幾種波束形成方法應用也比較廣泛,包括:基于最大信噪比的波束形成、基于多通道維納濾波的波束形成以及基于廣義旁瓣濾波的波束形成;通過數學表達式我們可以看出,噪聲協方差矩陣的估計起到了非常關鍵的作用。
下面重點介紹一下基于深度學習的波束形成方法;深度學習方法在智能語音領域的應用非常的廣泛,包括單通道的語音增強和語音去混響問題,深度學習方法已經成為了智能語音領域重要的主流方法之一;不同于單通道語音增強,多通道語音增強方法跟麥克風陣列的硬件結構高度相關,所以如果直接將各通道譜參數特征作為輸入,將干凈語音譜參數特征作為輸出,所訓練的模型將受限于硬件結構;因此,為了提高模型的泛化能力,更常用的方法是采用深層神經網絡模型對各個通道各個頻帶的屏蔽值進行估計、融合,進而計算出噪聲協方差矩陣,然后再跟傳統(tǒng)的波束形成方法對接,如下圖所示的方法是將深層神經網絡方法跟最小方差失真響應波束形成方法對接。
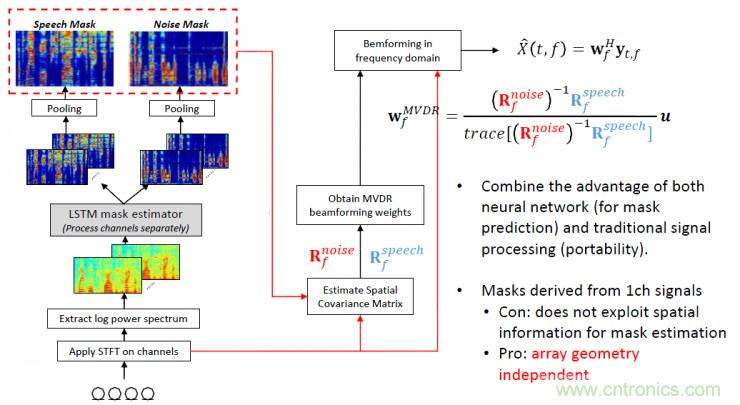
采用這種基于深度學習的方法,可以有效的抑制噪聲的干擾,提高增強語音的質量。增強后的語音可以輸入到語音識別系統(tǒng),提高語音識別的魯棒性。
四、語音前端處理方法在語音識別中的應用

這是用于遠場語音識別的公共數據庫,不同于近場語音識別數據庫,遠場語音數據的采集不僅錄音環(huán)境更為復雜,同時還跟采集語音的硬件相關。所以錄制遠場語音數據的成本相對較高。比較有名的遠場語音數據庫包括AMI數據,這個數據庫是在會議室環(huán)境下錄制的,混響時間較長;Chime數據庫,在噪聲環(huán)境下錄制的數據庫,其中Chime1和Chime2是單通道采集的,Chime-3和Chime-4是多通道采集的。
Chime-4比賽中包括了三種場景:單通道、雙通道和六通道。前端基線方法是改進的延時求和;后端聲學模型是7層的DNN,得到的聲學模型需要再進行sMBR區(qū)分性訓練;語言模型采用3元或5元的語言模型;語料內容來自WSJ0數據庫。
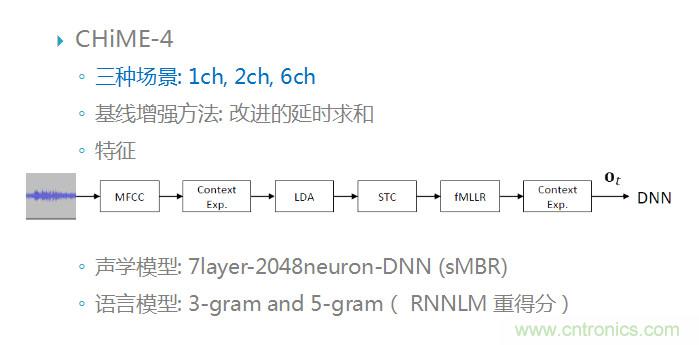
以下是對Chime-3和Chime-4比賽中的有效方法進行的梳理。
首先看一下前端部分,有效的估計噪聲協方差矩陣將有助于提高算法性能。為了有效的估計噪聲協方差矩陣,需要對各個通道的各個時頻單元進行屏蔽值估計,可以采用深度學習等方法進行估計,在此基礎上計算噪聲協方差矩陣;使用最多的波束形成方法包括:最小方差響應失真波束形成、最大信噪比波束形成、廣義旁瓣濾波波束形成、多通道維納濾波波束形成等。自適應波束形成方法要優(yōu)于固定波束形成方法。
接下來介紹后端有效方法,在數據選擇上充分利用各個通道數據;比如單通道語音增強任務,將六個通道采集的數據都作為訓練數據;前端算法和后端算法的匹配非常重要,具體來說,訓練聲學模型時,如果是將前端算法處理后的數據作為后端聲學模型的訓練數據,則對于測試集,需要先通過前端算法進行增強處理,然后在此基礎上通過后端模型識別;此外前端算法跟麥克風陣列的適配也是非常重要的。當前主流的聲學模型包括了BLSTM和深層的CNN;對不同的聲學模型進行融合也有助于提高識別率,比如將BLSTM和深層CNN的輸出層進行融合。對于語言模型LSTM優(yōu)于RNN,RNN優(yōu)于n-gram,對于工業(yè)領域的上線產品更多的是實用n-gram模型。
當前這一領域仍然面臨的挑戰(zhàn)和需要解決的痛點包括:
1、多說話人分離的雞尾酒問題,如何改進盲分離算法突破雞尾酒問題;
2、說話人移動時,如何保證遠場語音識別性能;
3、面對不同的麥克風陣列結構,如何提高語音前端算法的泛化性能;
4、面對更加復雜的非平穩(wěn)噪聲和強混響如何保證算法魯棒性;
5、針對更隨意的口語,尤其是窄帶語音,如何提高語音識別的性能;
6、遠場語音數據庫不容易采集,如何通過聲場環(huán)境模擬方法擴充數據庫。
上述問題的解決將有助于提高遠場語音識別算法的性能。
(本文由極限元智能科技語音算法專家、中科院-極限元“智能交互聯合實驗室”核心技術人員、中科院自動化所博士劉斌整理分享)
推薦閱讀:





